Poster Session 6 · Friday, December 5, 2025 4:30 PM → 7:30 PM
#100 Spotlight
Sheetpedia: A 300K-Spreadsheet Corpus for Spreadsheet Intelligence and LLM Fine-Tuning
Abstract
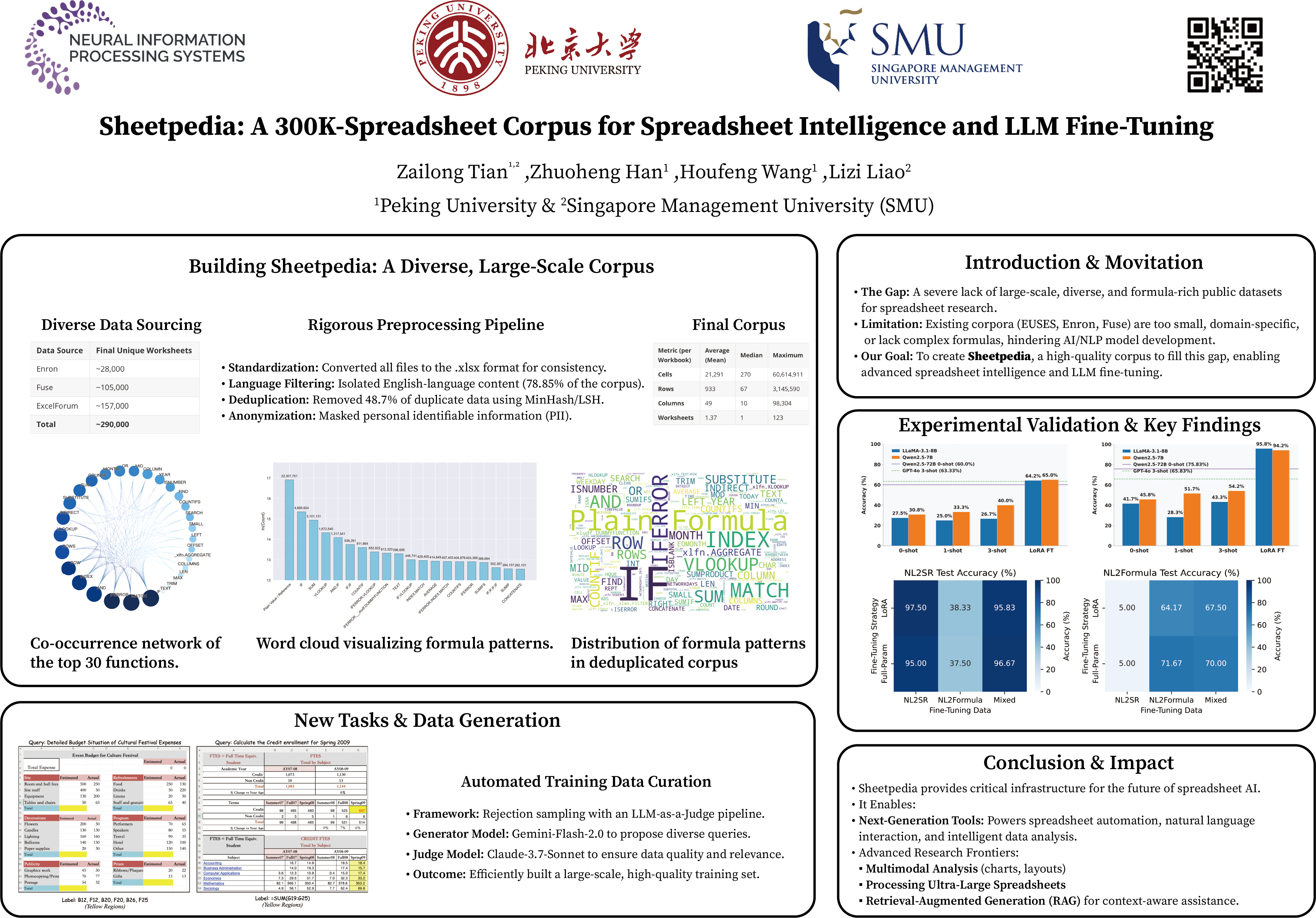
Spreadsheets are widely used for data analysis and reporting, yet their complex structure and formula logic pose significant challenges for AI systems. We introduce Sheetpedia, a large-scale corpus of over 290,000 diverse spreadsheets (from 324,000+ workbooks) compiled from enterprise email archives and online forums.
We detail a rigorous collection and preprocessing pipeline (integrating the Enron email spreadsheet archive and the Fuse web corpus, plus a new crawl of Excel forums) to standardize formats, filter languages, and remove duplicates. Sheetpedia provides extensive coverage of real formulas and annotations – addressing a gap left by prior table datasets (e.g., web tables used in TURL or Text-to-SQL in Spider) which often lack formula semantics.
We present comprehensive corpus statistics, highlighting rich formula diversity and a majority (78%+) of English content. To demonstrate the corpus’s utility, we fine-tune large language models on Sheetpedia for two novel spreadsheet understanding tasks: Natural Language to Semantic Range (NL2SR) and Natural Language to Formula (NL2Formula). Using a rejection-sampling data generation strategy, our fine-tuned models achieve up to 97.5% accuracy on NL2SR and 71.7% on NL2Formula – substantially outperforming baseline approaches.
Sheetpedia (to be released publicly) fills a crucial need for a large, high-quality spreadsheet benchmark, enabling more effective spreadsheet intelligence and natural language interfaces for spreadsheet tools.