Poster Session 1 · Wednesday, December 3, 2025 11:00 AM → 2:00 PM
#4707
FlexSelect: Flexible Token Selection for Efficient Long Video Understanding
Abstract
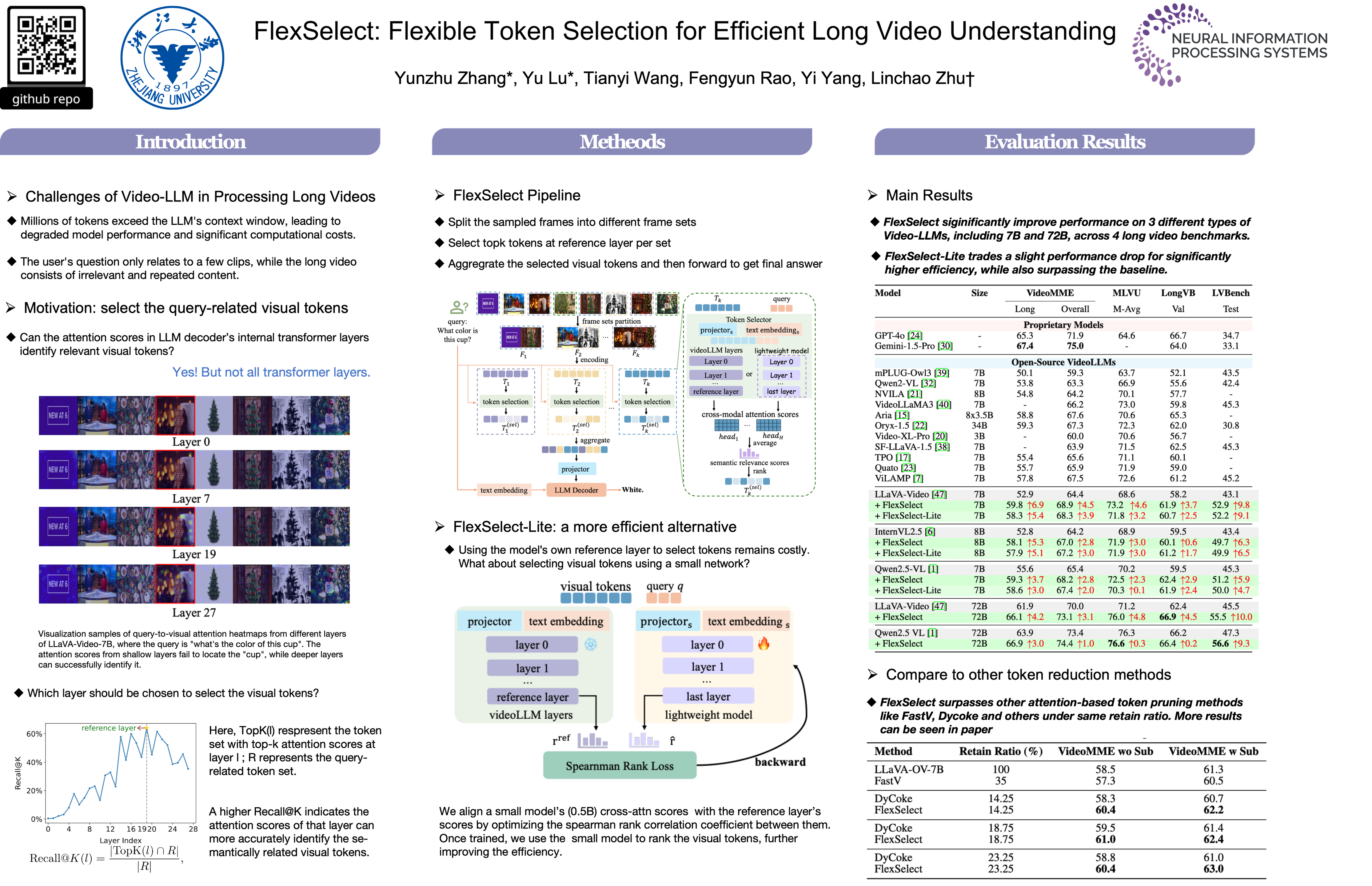
Long-form video understanding poses a significant challenge for video large language models (VideoLLMs) due to prohibitively high computational and memory demands. In this paper, We propose FlexSelect, a flexible and efficient token selection strategy for processing long videos.
FlexSelect identifies and retains the most semantically relevant content by leveraging cross-modal attention patterns from a reference transformer layer. It comprises two key components:
- a training-free token ranking pipeline that leverages faithful cross-modal attention weights to estimate each video token’s importance, and
- a rank-supervised lightweight selector that is trained to replicate these rankings and filter redundant tokens.
This generic approach can be seamlessly integrated into various VideoLLM architectures, such as LLaVA-Video, InternVL and Qwen-VL, serving as a plug-and-play module to extend their temporal context length. Empirically, FlexSelect delivers strong gains across multiple long-video benchmarks – including VideoMME, MLVU, LongVB, and LVBench. Morever, it achieves significant speed-ups (e.g., up to 9 on a LLaVA-Video-7B model), highlighting FlexSelect’s promise for efficient long-form video understanding.
Project page: https://flexselect.github.io