Poster Session 5 · Friday, December 5, 2025 11:00 AM → 2:00 PM
#805 Spotlight
SpecEdge: Scalable Edge-Assisted Serving Framework for Interactive LLMs
Abstract
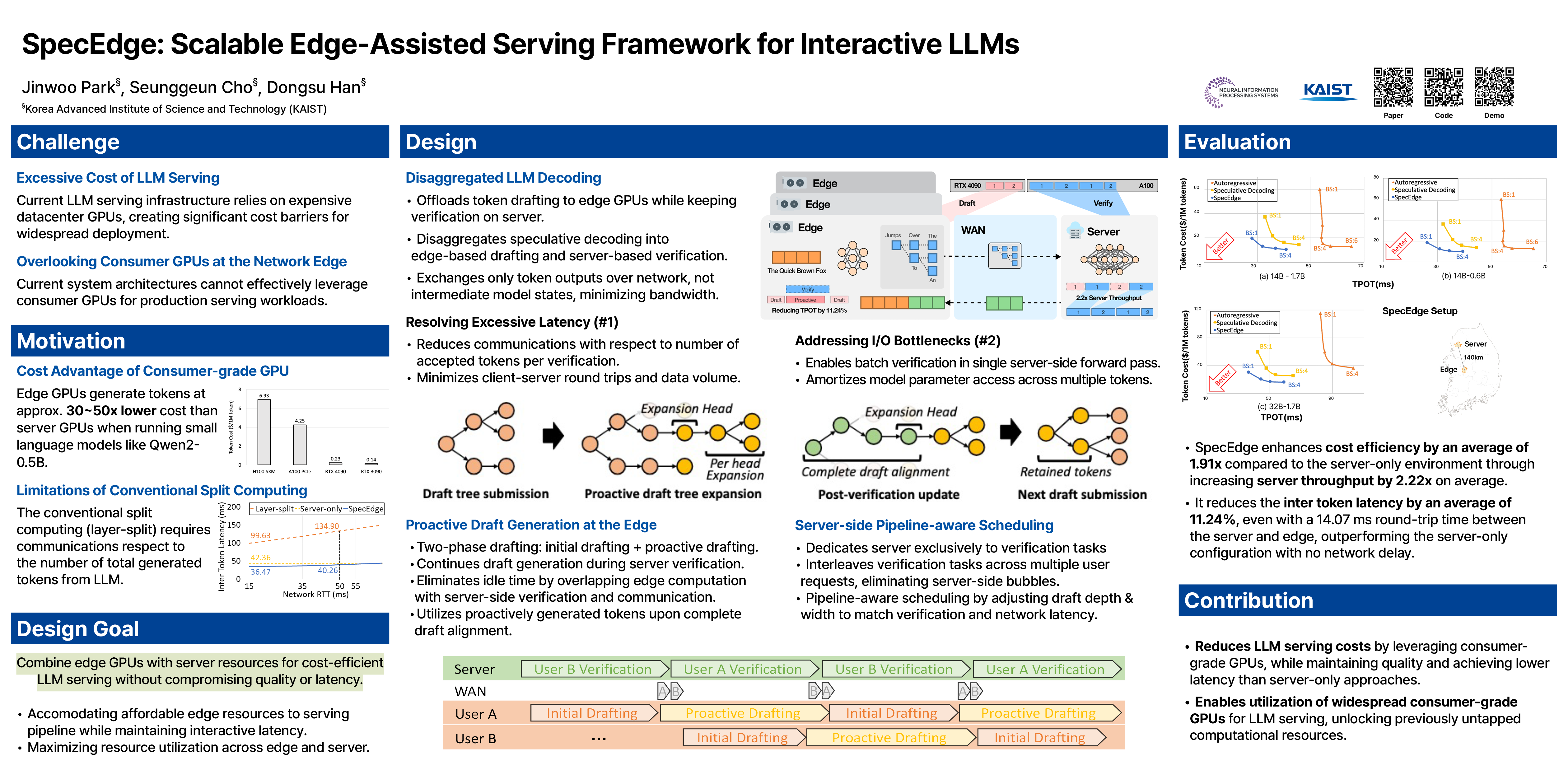
Large language models (LLMs) power many modern applications, but serving them at scale remains costly and resource-intensive. Current server-centric systems overlook consumer-grade GPUs at the edge.
We introduce SpecEdge, an edge-assisted inference framework that splits LLM workloads between edge and server GPUs using a speculative decoding scheme, exchanging only token outputs over the network.
SpecEdge employs proactive edge drafting to overlap edge token creation with server verification and pipeline-aware scheduling that interleaves multiple user requests to increase server-side throughput.
Experiments show SpecEdge enhances overall cost efficiency by 1.91× through achieving 2.22× server throughput, and reduces inter token latency by 11.24% compared to a server-only baseline, introducing a scalable, cost-effective paradigm for LLM serving.
The code is available at https://github.com/kaist-ina/specedge