Poster Session 5 · Friday, December 5, 2025 11:00 AM → 2:00 PM
#212
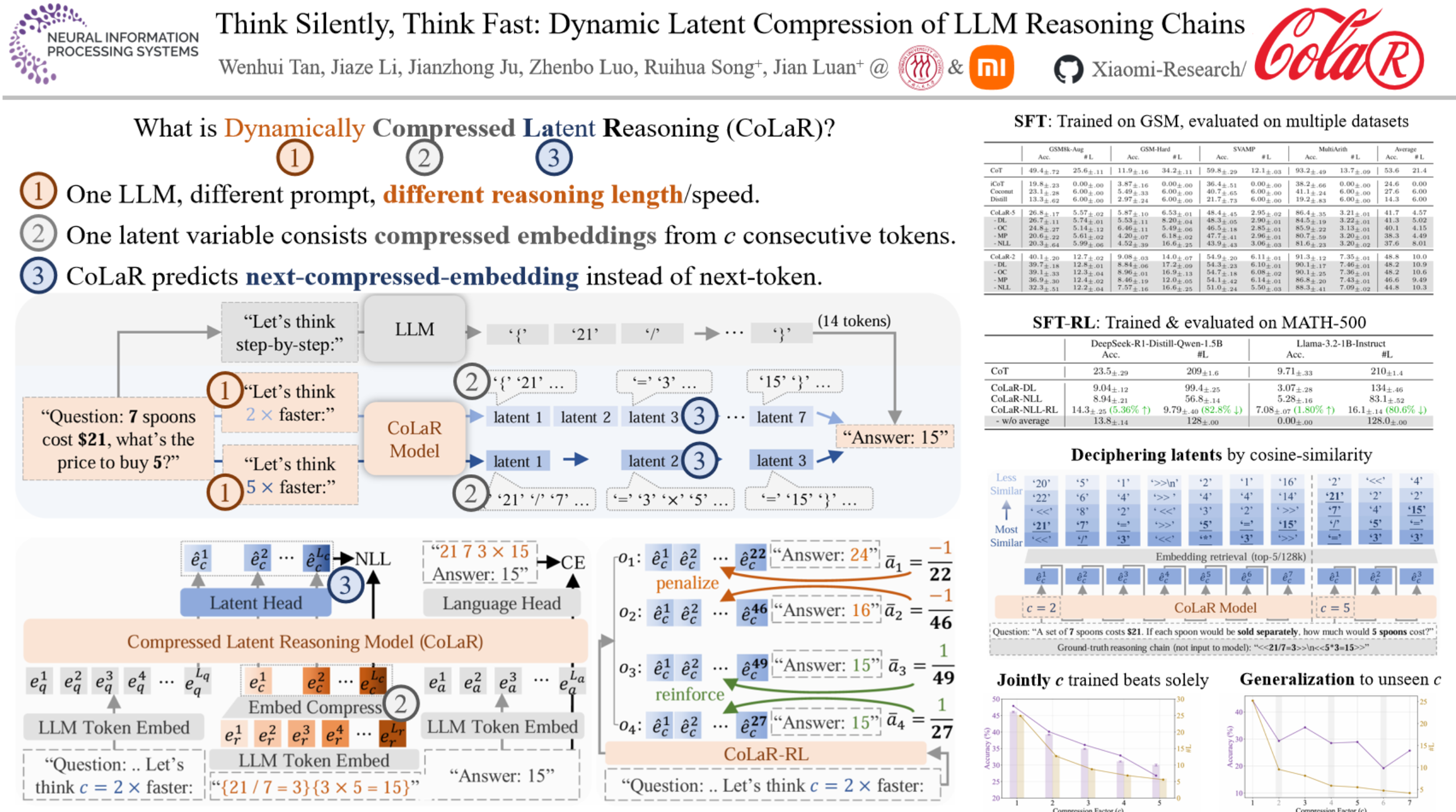
Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains
Abstract
Large Language Models (LLMs) achieve superior performance through Chain-of-Thought (CoT) reasoning, but these token-level reasoning chains are computationally expensive and inefficient.
In this paper, we introduce Compressed Latent Reasoning (CoLaR), a novel framework that dynamically compresses reasoning processes in latent space through a two-stage training approach.
First, during supervised fine-tuning, CoLaR extends beyond next-token prediction by incorporating an auxiliary next compressed embedding prediction objective. This process merges embeddings of consecutive tokens using a compression factor randomly sampled from a predefined range, and trains a specialized latent head to predict distributions of subsequent compressed embeddings. Second, we enhance CoLaR through reinforcement learning (RL) that leverages the latent head's non-deterministic nature to explore diverse reasoning paths and exploit more compact ones.
This approach enables CoLaR to:
- perform reasoning at a dense latent level (i.e., silently), substantially reducing reasoning chain length, and
- dynamically adjust reasoning speed at inference time by simply prompting the desired compression factor.
Extensive experiments across four mathematical reasoning datasets demonstrate that CoLaR achieves 14.1% higher accuracy than latent-based baseline methods at comparable compression ratios, and reduces reasoning chain length by 53.3% with only 4.8% performance degradation compared to explicit CoT method. Moreover, when applied to more challenging mathematical reasoning tasks, our RL-enhanced CoLaR demonstrates performance gains of up to 5.4% while dramatically reducing latent reasoning chain length by 82.8%. The code and models will be released upon acceptance.