Poster Session 1 · Wednesday, December 3, 2025 11:00 AM → 2:00 PM
#4313
RelationAdapter: Learning and Transferring Visual Relation with Diffusion Transformers
Abstract
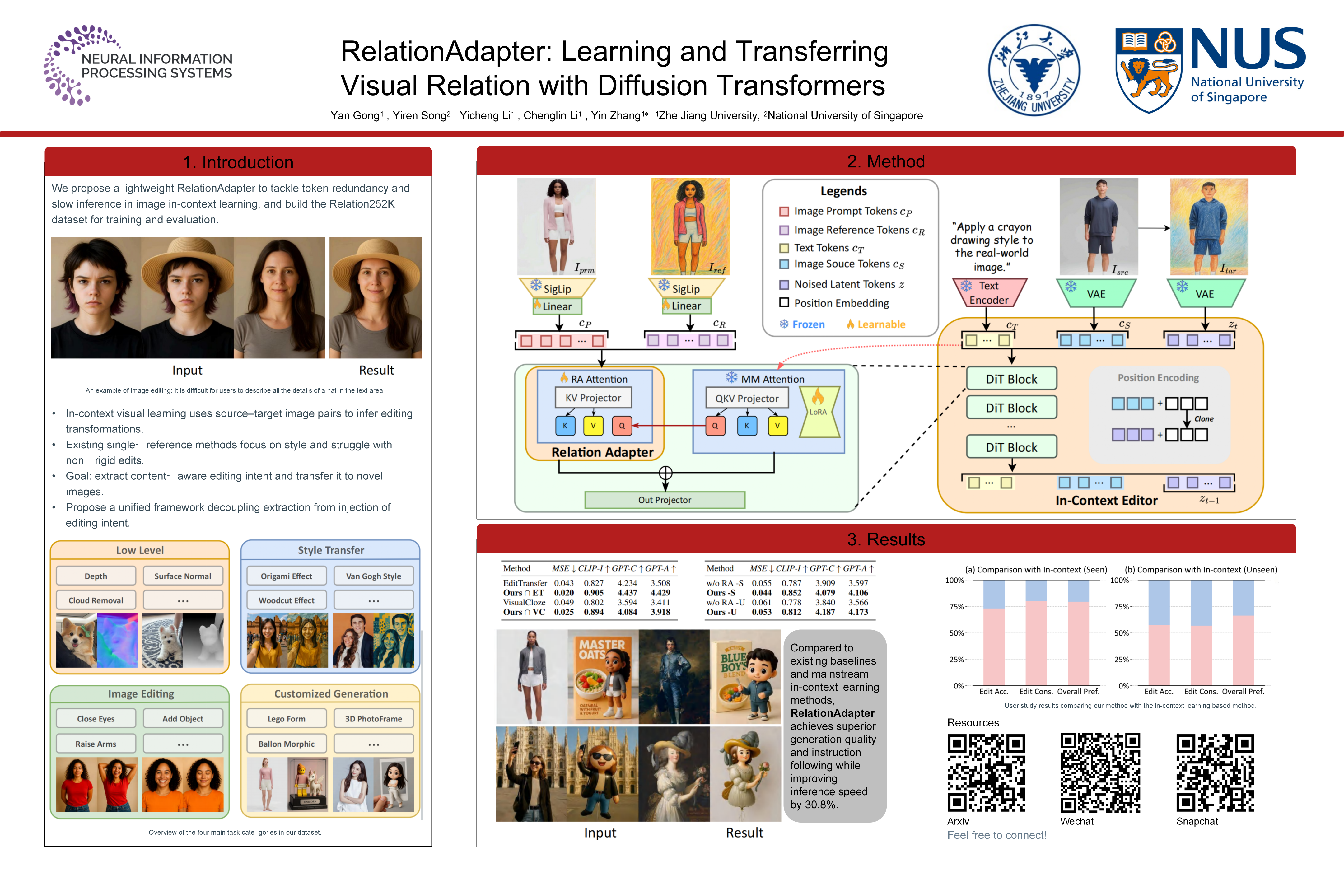
Inspired by the in-context learning mechanism of large language models (LLMs), a new paradigm of generalizable visual prompt-based image editing is emerging. Existing single-reference methods typically focus on style or appearance adjustments and struggle with non-rigid transformations.
To address these limitations, we propose leveraging source-target image pairs to extract and transfer content-aware editing intent to novel query images. To this end, we introduce RelationAdapter, a lightweight module that enables Diffusion Transformer (DiT) based models to effectively capture and apply visual transformations from minimal examples.
We also introduce Relation252K, a comprehensive dataset comprising 218 diverse editing tasks, to evaluate model generalization and adaptability in visual prompt-driven scenarios. Experiments on Relation252K show that RelationAdapter significantly improves the model’s ability to understand and transfer editing intent, leading to notable gains in generation quality and overall editing performance.