Poster Session 4 · Thursday, December 4, 2025 4:30 PM → 7:30 PM
#708 Spotlight
MGUP: A Momentum-Gradient Alignment Update Policy for Stochastic Optimization
Abstract
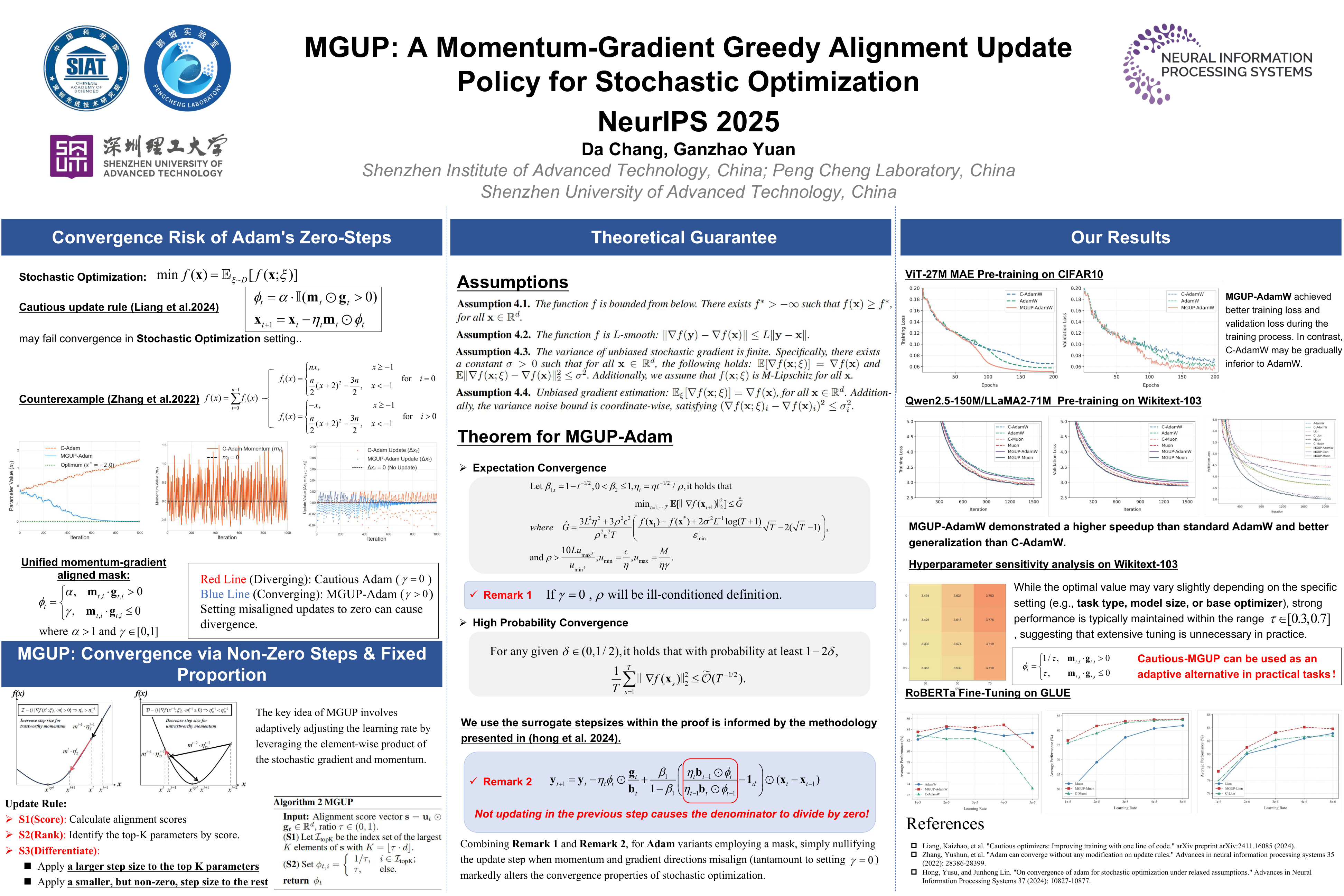
Efficient optimization is essential for training large language models. Although intra-layer selective updates have been explored, a general mechanism that enables fine-grained control while ensuring convergence guarantees is still lacking.
To bridge this gap, we propose MGUP, a novel mechanism for selective updates. MGUP augments standard momentum-based optimizers by applying larger step-sizes to a selected fixed proportion of parameters in each iteration, while applying smaller, non-zero step-sizes to the rest. As a nearly {plug-and-play} module, MGUP seamlessly integrates with optimizers such as AdamW, Lion, and Muon. This yields powerful variants such as MGUP-AdamW, MGUP-Lion, and MGUP-Muon.
Under standard assumptions, we provide theoretical convergence guarantees for MGUP-AdamW (without weight decay) in stochastic optimization. Extensive experiments across diverse tasks, including MAE pretraining, LLM pretraining, and downstream fine-tuning, demonstrate that our MGUP-enhanced optimizers achieve superior or more stable performance compared to their original base optimizers.
We offer a principled, versatile, and theoretically grounded strategy for efficient intra-layer selective updates, accelerating and stabilizing the training of large-scale models. The code is publicly available at https://github.com/MaeChd/MGUP.