Poster Session 2 · Wednesday, December 3, 2025 4:30 PM → 7:30 PM
#4706
ExGra-Med: Extended Context Graph Alignment for Medical Vision-Language Models
Duy Minh Ho Nguyen, Nghiem Tuong Diep, Trung Quoc Nguyen, Hoang-Bao Le, Tai Nguyen, Anh-Tien Nguyen, TrungTin Nguyen, Nhat Ho, Pengtao Xie, Roger Wattenhofer, Daniel Sonntag, James Zou, Mathias Niepert
DFKI· Max Planck Research School for Intelligent Systems (IMPRS-IS)· University of Stuttgart· University Medical Center Göttingen· Max Planck Institute for Multidisciplinary Sciences· ARC Centre of Excellence for the Mathematical Analysis of Cellular Systems· Queensland University of Technology· University of Oldenburg· UT Austin· UC San Diego· MBZUAI· ETH· Stanford
Abstract
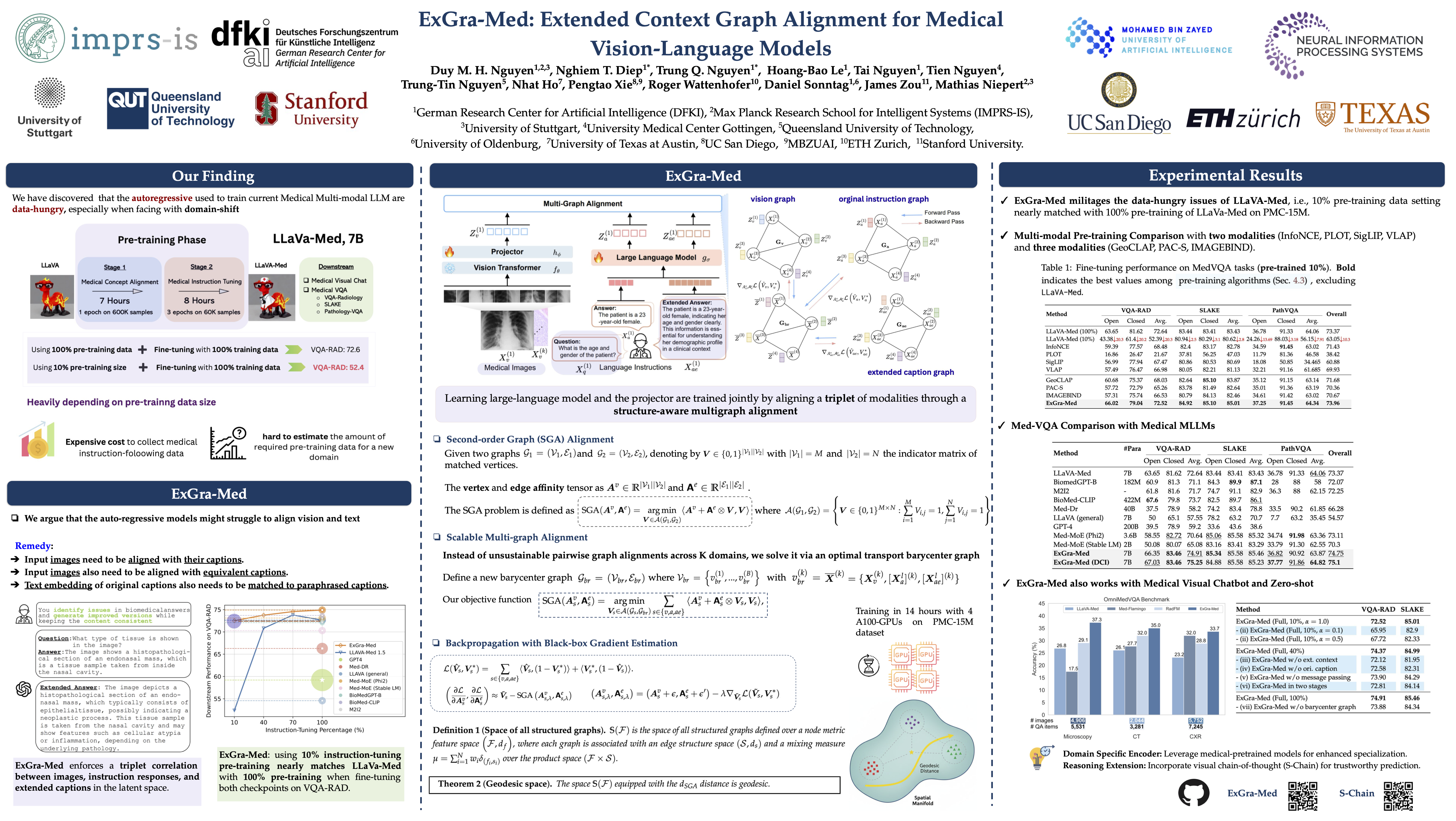
State-of-the-art medical multi-modal LLMs (med-MLLMs), such as LLaVA-Med and BioMedGPT, primarily depend on scaling model size and data volume, with training driven largely by autoregressive objectives.
However, we reveal that this approach can lead to weak vision-language alignment, making these models overly dependent on costly instruction-following data. To address this, we introduce ExGra-Med, a novel multi-graph alignment framework that jointly aligns images, instruction responses, and extended captions in the latent space, advancing semantic grounding and cross-modal coherence.
To scale to large LLMs (e.g., LLaMa-7B), we develop an efficient end-to-end training scheme using black-box gradient estimation, enabling fast and scalable optimization.
Empirically, ExGra-Med matches LLaVA-Med's performance using just 10% of pre-training data, achieving a 20.13% gain on VQA-RAD and approaching full-data performance. It also outperforms strong baselines like BioMedGPT and RadFM on visual chatbot and zero-shot classification tasks, demonstrating its promise for efficient, high-quality vision-language integration in medical AI.