Poster Session 2 · Wednesday, December 3, 2025 4:30 PM → 7:30 PM
#907
Pay Attention to Small Weights
Abstract
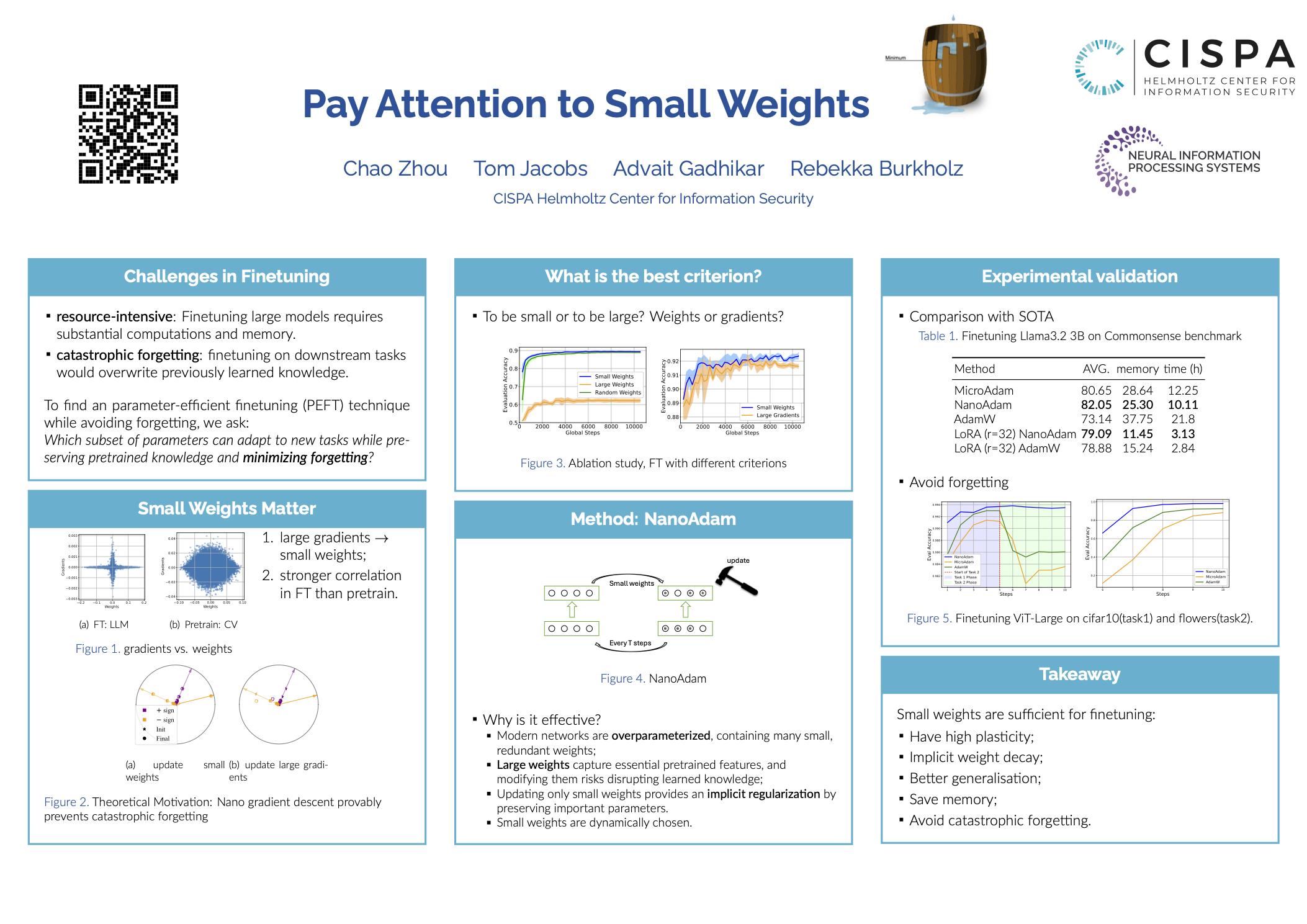
Finetuning large pretrained neural networks is known to be resource-intensive, both in terms of memory and computational cost. To mitigate this, a common approach is to restrict training to a subset of the model parameters.
By analyzing the relationship between gradients and weights during finetuning, we observe a notable pattern: large gradients are often associated with small-magnitude weights. This correlation is more pronounced in fine-tuning settings than in training from scratch.
Motivated by this observation, we propose NanoAdam, which dynamically updates only the small-magnitude weights during fine-tuning and offers several practical advantages:
- first, the criterion is gradient-free—the parameter subset can be determined without gradient computation;
- second, it preserves large-magnitude weights, which are likely to encode critical features learned during pre-training, thereby reducing the risk of catastrophic forgetting;
- thirdly, it permits the use of larger learning rates and consistently leads to better generalization performance in experiments.
We demonstrate this for both NLP and vision tasks.