Poster Session 6 · Friday, December 5, 2025 4:30 PM → 7:30 PM
#3718 Spotlight
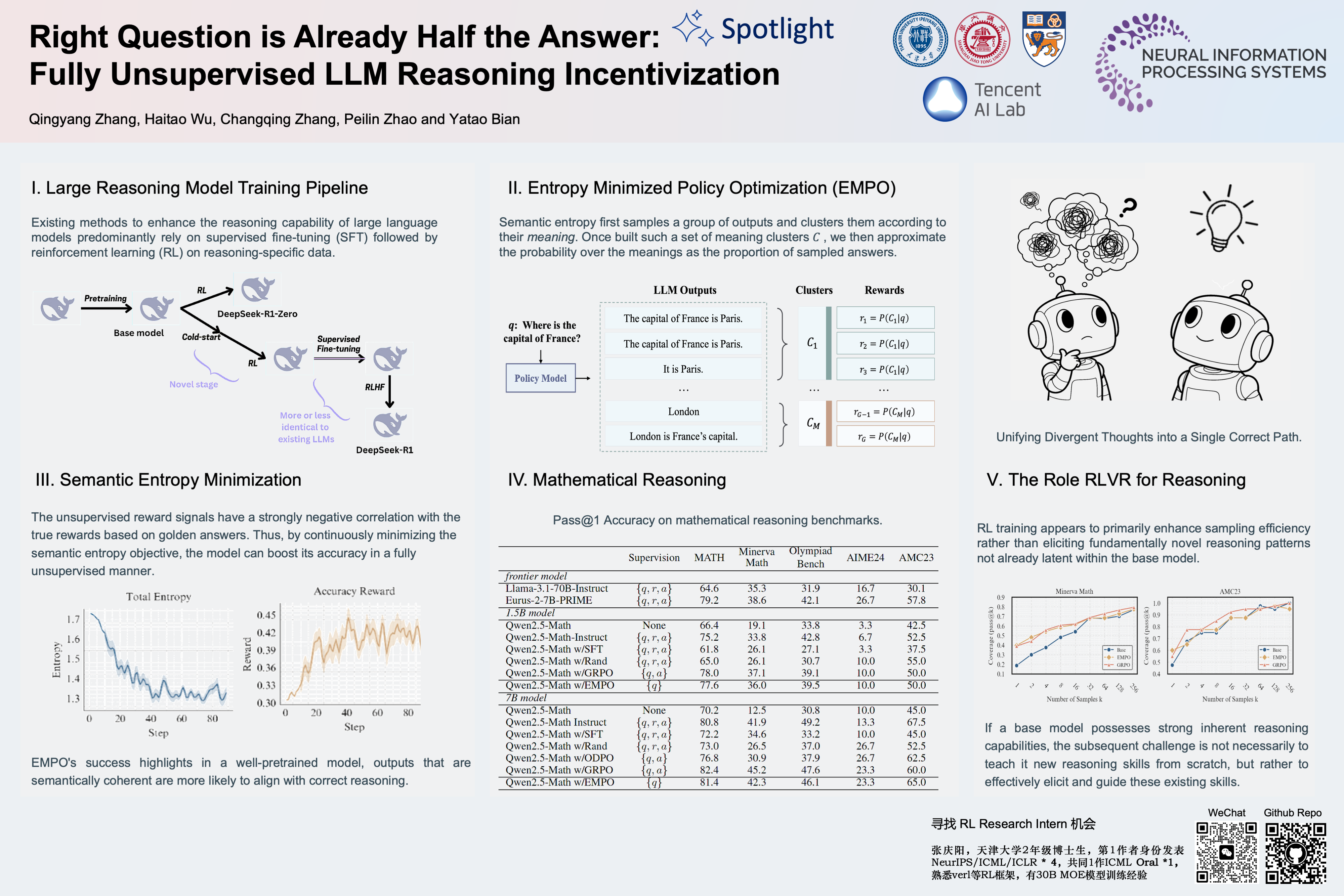
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Abstract
Existing methods to enhance the reasoning capability of large language models predominantly rely on supervised fine-tuning (SFT) followed by reinforcement learning (RL) on reasoning-specific data. These approaches critically depend on external supervisions-- such as labeled reasoning traces, verified golden answers, or pre-trained reward models.
In this work, we propose Entropy Minimized Policy Optimization (EMPO), which makes an early attempt at fully unsupervised LLM reasoning incentivization. By minimizing the semantic entropy of LLMs on unlabeled questions, EMPO achieves competitive performance compared to supervised counterparts.
Specifically, without any supervised signals, EMPO boosts the accuracy of Qwen2.5-Math-7B Base from 33.7% to 51.6% on math benchmarks and improves the accuracy of Qwen2.5-7B Base from 32.1% to 50.1% on MMLU-Pro. Primary analysis are also provided to interpret the effectiveness of EMPO. Code is available at https://github.com/QingyangZhang/EMPO.