Poster Session 2 · Wednesday, December 3, 2025 4:30 PM → 7:30 PM
#4811
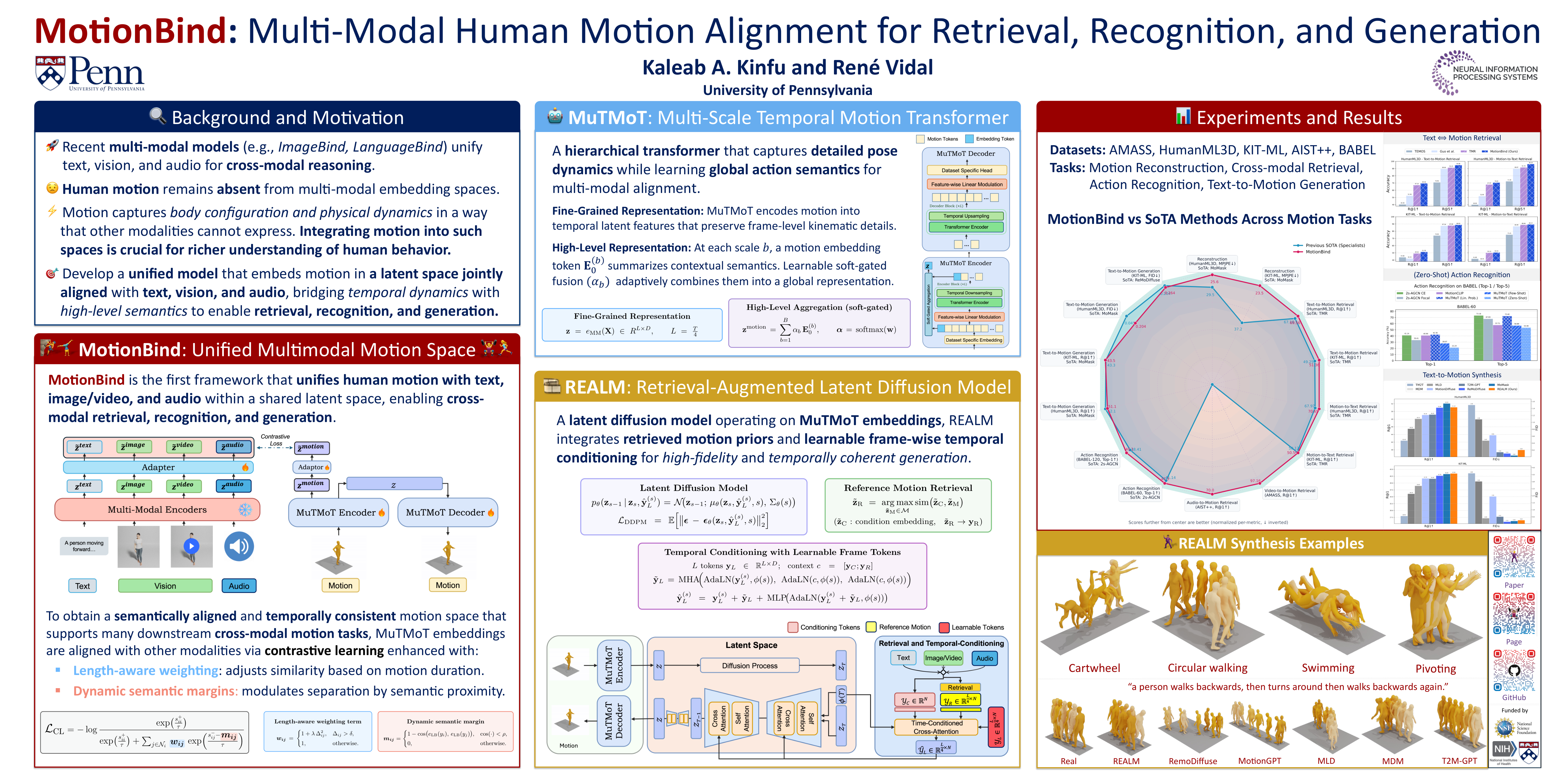
MotionBind: Multi-Modal Human Motion Alignment for Retrieval, Recognition, and Generation
Abstract
Recent advances in multi-modal representation learning have led to unified embedding spaces that align modalities such as images, text, audio, and vision. However, human motion sequences, a modality that is fundamental for understanding dynamic human activities, remains largely unrepresented in these frameworks. Semantic understanding of actions requires multi-modal grounding: text conveys descriptive semantics, vision provides visual context, and audio provides environmental cues.
To bridge this gap, we propose MotionBind, a novel architecture that extends the LanguageBind embedding space to incorporate human motion.
MotionBind has two major components. The first one is a Multi-Scale Temporal Motion Transformer (MuTMoT) that maps motion sequences to semantically meaningful embeddings. Multimodal alignment is achieved via diverse cross-modal supervision, including motion-text pairs from HumanML3D and KIT-ML, motion-video pairs rendered from AMASS, and motion-video-audio triplets from AIST++.
The second component is a Retrieval-Augmented Latent diffusion Model (REALM) that can generate motion sequences conditioned on many modalities.
MotionBind achieves state-of-the-art or competitive performance across motion reconstruction, cross-modal retrieval, zero-shot action recognition, and text-to-motion generation benchmarks.