Poster Session 1 · Wednesday, December 3, 2025 11:00 AM → 2:00 PM
#4208
Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
Shiwei Li, Xiandi Luo, Haozhao Wang, Xing Tang, Ziqiang Cui, Dugang Liu, Yuhua Li, xiuqiang He, Ruixuan Li
Abstract
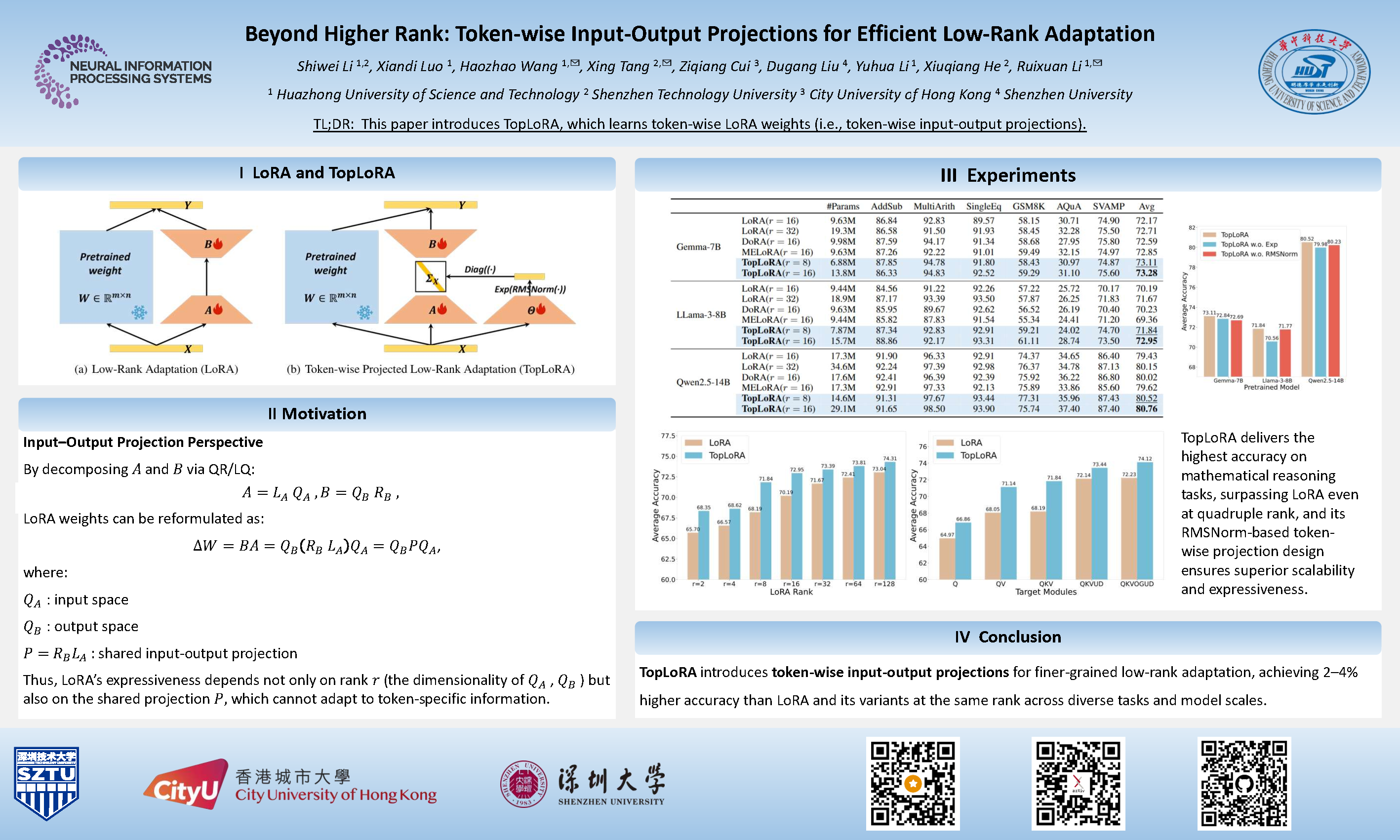
Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank.
In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens.
To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as , where and are low-rank matrices (as in standard LoRA), and is a diagonal matrix generated from each input token .
Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.